|
| 1 | +- Feature Name: `k6_tests_cluster` |
| 2 | +- Start Date: 2025-01-09 |
| 3 | +- RFC PR: [altinn/altinn-platform#1211](https://github.com/Altinn/altinn-platform/pull/1211) |
| 4 | +- Github Issue: [altinn/altinn-platform#1150](https://github.com/Altinn/altinn-platform/issues/1150) |
| 5 | +- Product/Category: Monitoring |
| 6 | +- State: **REVIEW** |
| 7 | + |
| 8 | +# Summary |
| 9 | +[summary]: #summary |
| 10 | + |
| 11 | +This RFC proposes a Platform managed k8s cluster that developers can use to run K6 Tests from. |
| 12 | +The cluster is multi-tenant - meaning multiple teams will share the same cluster but each team |
| 13 | +will have it's own namespace. |
| 14 | + |
| 15 | +The cluster can offer a variety of nodes with different specs to accomodate |
| 16 | +different workloads. A mix of ["on-demand"](https://learn.microsoft.com/en-us/azure/aks/core-aks-concepts#vm-size-and-image) and |
| 17 | +["spot"](https://learn.microsoft.com/en-us/azure/virtual-machines/spot-vms) node pools are available and developers can |
| 18 | +select which nodes are needed depending on their needs. The node pools autoscale to accomodate |
| 19 | +workload needs and are shared by multiple teams. There is, of course, the possibility of requesting dedicated |
| 20 | +nodes if the need arises. |
| 21 | + |
| 22 | +The solution also offers automatic test metrics storage in Azure Monitor Workspace (AMW) and visualization in Grafana by taking advantage of the |
| 23 | +predefined Grafana dashboards from both k6 and Azure. More specific dashboards can be developed and |
| 24 | +shared between the teams as well as further integrations (e.g. with app insights or log analytics). |
| 25 | + |
| 26 | +Secret managed is implemented with SealedSecrets in cases where the tests need some sort of |
| 27 | +authentication. |
| 28 | + |
| 29 | +For extra feedback on the tests and the systems being tested we also support notifications via AlertManager and github commit status updates. |
| 30 | + |
| 31 | +The interface for developers will be simple YAML file with the necessary configurations needed from them. |
| 32 | +The k8s resources will be generated with Jsonnet based on the configs provided in the config file. |
| 33 | + |
| 34 | +A Github Action that can be re-used by various teams will be maintained by the Platform team for simple integration and maintainability. |
| 35 | + |
| 36 | +# Motivation |
| 37 | +[motivation]: #motivation |
| 38 | + |
| 39 | +The initial requirements came from Dagfinn as he needed a place to |
| 40 | +store the metrics related to the performance tests he was running and also more performant nodes to |
| 41 | +run the tests from as the nodes provided by Github (via Github Actions) were not performant |
| 42 | +enough. It also seems like a good idea to standardize the way k6 tests are run throughout the company. |
| 43 | +Ideally, we should make it easy for developers to write the tests themselves instead of relying on |
| 44 | +a small group of people to write them all. |
| 45 | + |
| 46 | +# Guide-level explanation |
| 47 | +[guide-level-explanation]: #guide-level-explanation |
| 48 | +> [!WARNING] |
| 49 | +> Workflow is outdated but the general idea is still valid. |
| 50 | + |
| 51 | + |
| 52 | +The expected workflow should be: |
| 53 | +- Developers write down their k6 scripts. |
| 54 | +- They create a team platform specific config file with basic information related to the tests such as |
| 55 | +the entry point for the tests, node requirements, credentials needed, number of instances, etc. |
| 56 | +- They push their code to their Github repo. |
| 57 | +- We provide the automation via a Github Action that reads the config file and generate the boilerplate needed |
| 58 | +to run the tests and deploy the manifests into the k8s cluster. |
| 59 | +- The tests run, |
| 60 | +- Developers check the Grafana dashboards / Github status checks if they are interested on the results or wait for |
| 61 | +potential notifications from AlertManager. |
| 62 | + |
| 63 | +# Reference-level explanation |
| 64 | +[reference-level-explanation]: #reference-level-explanation |
| 65 | + |
| 66 | +Onboarding a new Team requires some setup beforehand. |
| 67 | +First, it's assumed that teams already have a [Service Principal](https://docs.github.com/en/actions/security-for-github-actions/security-hardening-your-deployments/configuring-openid-connect-in-azure) |
| 68 | +that they are using to authenticate towards Azure from Github. |
| 69 | + |
| 70 | +On our end, we need to create a namespace for the team, create the necessary Entra ID Groups, add the necessary members to the group and create the k8s RoleBindings. [Azure docs for an overview of the needed steps.](https://learn.microsoft.com/en-us/azure/aks/azure-ad-rbac) |
| 71 | +Ideally, these will be done in a automated way but as of right now we have to do this manually. |
| 72 | + |
| 73 | +There are 4 general groups defined: |
| 74 | +- Cluster Admin: has the [`Azure Kubernetes Service Cluster Admin Role`](https://learn.microsoft.com/en-us/azure/role-based-access-control/built-in-roles/containers#azure-kubernetes-service-cluster-admin-role) to allow us to List cluster admin credential whenever we need to do anything in the cluster. It's also required by whatever ServicePrincipal we decide to use to manage resources in the cluster, e.g. to create the namespaces per team, create the role bindings, deploy services we might want to provide in cluster, etc. It's a [super-user access](https://kubernetes.io/docs/reference/access-authn-authz/rbac/#user-facing-roles). In the future we might want to use this Group/Role only in exceptional cases and instead, create CustomRole with the permissions we know we need and another a CustomRole for the permissions needed by the Service Principal. And for us, we can use PIM when needed. |
| 75 | + |
| 76 | +- Cluster User: has the [`Azure Kubernetes Service Cluster User Role`](https://learn.microsoft.com/en-us/azure/role-based-access-control/built-in-roles/containers#azure-kubernetes-service-cluster-user-role) to allow users (humans and service principals) to List cluster user credentials. This is what will allow them to interact with the cluster via kubectl for example. |
| 77 | + |
| 78 | +- ${TEAM_NAME} Users - The object id will be used in the k8s RoleBinding to set the permissions that developers need to debug issues on the cluster - [example config](https://github.com/Altinn/altinn-platform/blob/d37e379417b1886f6d17816ba70bfae5ac664c32/infrastructure/adminservices-test/altinn-monitor-test-rg/k6_tests_rg_rbac.tf#L1-L31). This is a group per team. |
| 79 | + |
| 80 | +- ${TEAM_SP} Users - The object id will be used in the k8s RoleBinding to set the permissions that service principals need to deploy k8s resources on the cluster - [example config](https://github.com/Altinn/altinn-platform/blob/d37e379417b1886f6d17816ba70bfae5ac664c32/infrastructure/adminservices-test/altinn-monitor-test-rg/k6_tests_rg_rbac.tf#L33-L63). This is a group per team. If a team has multiple repos, we can add the various SPs to the same group. (If they prefer to keep it separate, we can also follow the normal process as if it was a completely different team). |
| 81 | + |
| 82 | +Once we've done our part, developers need to setup their own Github Workflow that references our GithubAction and fill out a config file that we use to generate the deployment manifests. The current implementation uses a simple yaml file as the config format and Jsonnet to create the needed manifests. |
| 83 | + |
| 84 | +``` |
| 85 | +test_run: |
| 86 | + name: k6-enduser-search |
| 87 | + vus: 50 |
| 88 | + duration: 10m |
| 89 | + parallelism: 10 |
| 90 | + file_path: "/path/to/where/test/files/are/located" |
| 91 | +``` |
| 92 | +The Github Action is a [composite action](https://docs.github.com/en/actions/sharing-automations/creating-actions/creating-a-composite-action) that runs a docker image with the needed tools and scripts to setup the environment, generate the needed k6 and k8s resources and deploys starts the test by deploying the manifests into the cluster. |
| 93 | + |
| 94 | +Some of the steps include [creating a .tar file](https://grafana.com/docs/k6/latest/misc/archive/), creating a ConfigMap to hold the archive file, creating optional SealedSecrets with encrypted data and generating the actual [TestRun Custom Resource](https://grafana.com/docs/k6/latest/testing-guides/running-distributed-tests/#4-create-a-custom-resource). Other useful things such as adding labels, default test id values, etc. that are useful for integrating with other systems are also handled by the action. |
| 95 | + |
| 96 | +An example of a TestRun config can be seen below. |
| 97 | + |
| 98 | +``` |
| 99 | +apiVersion: k6.io/v1alpha1 |
| 100 | +kind: TestRun |
| 101 | +metadata: |
| 102 | + name: k6-create-transmissions |
| 103 | + namespace: dialogporten |
| 104 | +spec: |
| 105 | + arguments: --out experimental-prometheus-rw --vus=10 --duration=5m --tag testid=k6-create-transmissions_20250109T082811 |
| 106 | + parallelism: 5 |
| 107 | + script: |
| 108 | + configMap: |
| 109 | + name: k6-create-transmissions |
| 110 | + file: archive.tar |
| 111 | + runner: |
| 112 | + env: |
| 113 | + - name: K6_PROMETHEUS_RW_SERVER_URL |
| 114 | + value: "http://kube-prometheus-stack-prometheus.monitoring:9090/api/v1/write" |
| 115 | + - name: K6_PROMETHEUS_RW_TREND_STATS |
| 116 | + value: "avg,min,med,max,p(95),p(99),p(99.5),p(99.9),count" |
| 117 | + metadata: |
| 118 | + labels: |
| 119 | + k6-test: k6-create-transmissions |
| 120 | + resources: |
| 121 | + requests: |
| 122 | + memory: 200Mi |
| 123 | +``` |
| 124 | + |
| 125 | +As the test is running, Grafana can be used to check the behavior in real time. |
| 126 | + |
| 127 | +For developers that would like to have smoke tests implemented after every commit to main, it's possible use the [github api](https://docs.github.com/en/rest/commits/statuses?apiVersion=2022-11-28) to do it. For those who wish it, it's also possible to use [AlertManager](https://prometheus.io/docs/alerting/latest/configuration/#receiver) to generate notifications to systems such as Slack. |
| 128 | + |
| 129 | +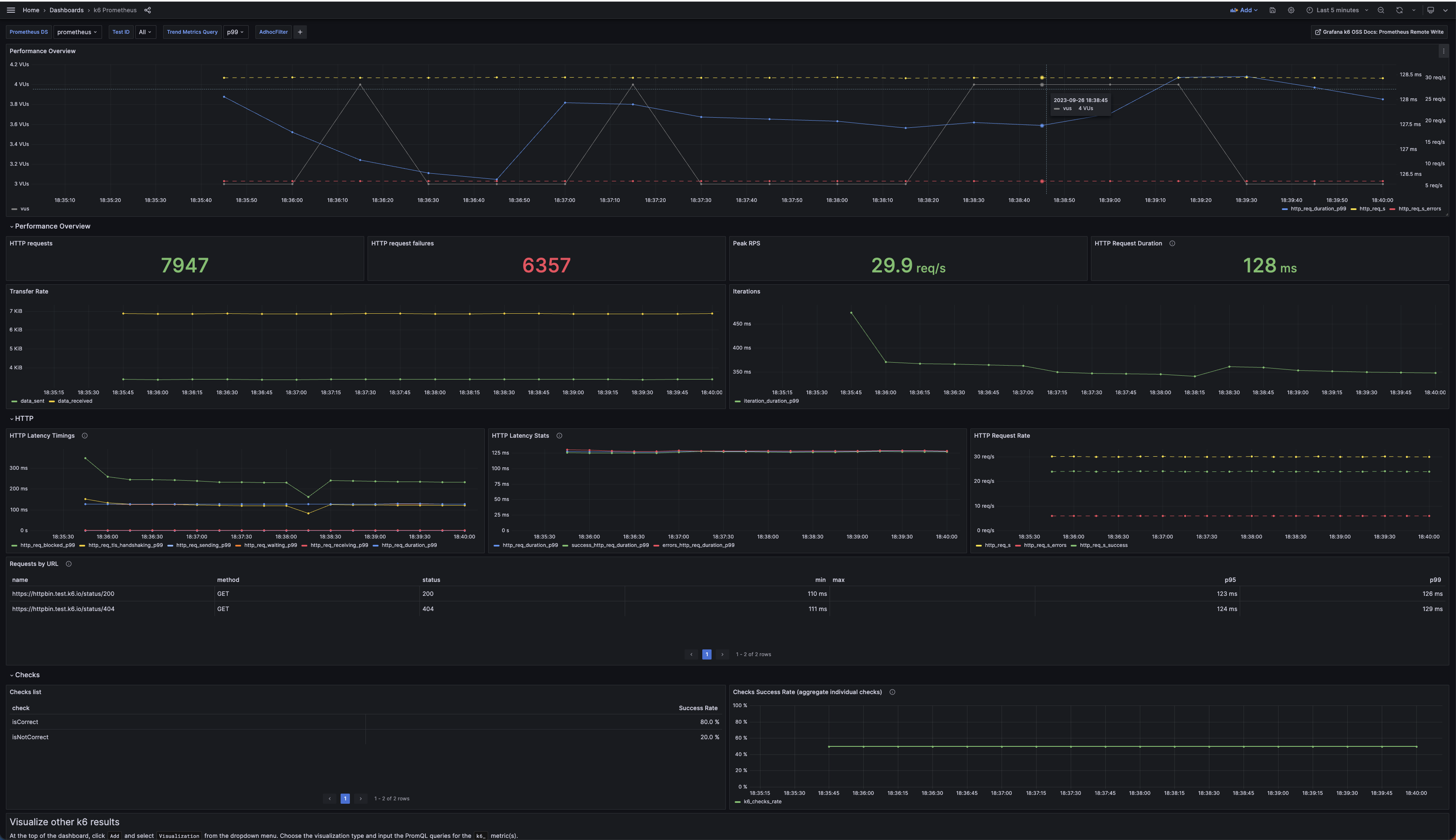 |
| 130 | + |
| 131 | +## Infrastructure |
| 132 | +The main infrastructure needed are a k8s clusters (for running the tests and other supporting services) and an Azure Monitor Workspace for storing the Prometheus metrics generated by the test runs. |
| 133 | + |
| 134 | +Some of the main requirements from the cluster are: [the enablement of OIDC issuer and workload identity](https://learn.microsoft.com/en-us/azure/aks/workload-identity-deploy-cluster), which are needed for example to configure Prometheus to write metrics into the Azure Monitor Workspace. [Entra ID with Kubernetes RBAC](https://learn.microsoft.com/en-us/azure/aks/azure-ad-rbac?tabs=portal) so that we can define permissions per namespace and per user type/role. And the [deployment of multiple node pools](https://learn.microsoft.com/en-us/azure/aks/manage-node-pools) with different labels in order to be able to define [where specific workloads need to run on](https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/). |
| 135 | + |
| 136 | +The amount of node pools needed will vary depending on the use cases we end up supporting and it's a relatively easy process to add and remove node pools from the cluster. (TODO: I had some issues a few years ago where if we scaled a node pool to zero it would not scale up when workloads needed to be scheduled. There are mitigations for this but hopefully the nodes will scale up automatically now.) The process of adding the necessary config into the TestRun k8s manifest should be abstract from the users to avoid silly misconfigurations. |
| 137 | + |
| 138 | +The cluster should also be configured in a while requires the least amount of maintenance possible, e.g. by [allowing automatic updates](https://learn.microsoft.com/en-us/azure/aks/auto-upgrade-cluster?tabs=azure-cli#cluster-auto-upgrade-channels). |
| 139 | + |
| 140 | + |
| 141 | +To visualize the data stored in the Azure Monitor Workspace, we need to add a azure_monitor_workspace_integrations block in the centralized monitoring azurerm_dashboard_grafana. A new datasource will then available in Grafana for data querying. |
| 142 | + |
| 143 | +Azure also provides a few out-of-the-box dashboards that can be used to monitor the state of the cluster. We also import other OSS dashboards as needed; such as the [K6 operator dashboard](https://grafana.com/grafana/dashboards/19665-k6-prometheus/). |
| 144 | + |
| 145 | +### Services |
| 146 | +There are also a few services we need to maintain; mainly a Prometheus instance that is used as [the remote write target by the test pods](https://grafana.com/docs/k6/latest/results-output/real-time/prometheus-remote-write/) which then [forwards the metrics to the Azure Monitor Worspace](https://learn.microsoft.com/en-us/azure/azure-monitor/containers/prometheus-remote-write-managed-identity). Currently, the config is quite simple. The Prometheus instance was deployed via kube-prometheus-stack's Helm Chart together with AlertManager. Prometheus needs to be configured to use Workload Identity in order for it to be able to push metrics to the Azure Monitor Workspace. The rest of the prometheus configs tweaked so far were: Addition of externalLabels (likely not needed if we only use a single cluster), enableRemoteWriteReceiver to support receiving metrics via Remote Write from the test pods, a low retention period as the objective at the moment is only to keep the metrics long enough until they are remote writed to AMW (This might need to be tweaks depending on how we end up using AlertManager), configuration of the volumeClaimTemplate to select an appropriate disk type and size, and a remote write configuration block that points to the Azure Monitor Workspace. The K8s manifests also need some tweaks, mainly the ServiceAccount and Pod need some Workload Identity Labels and Annotations respectively. |
| 147 | + |
| 148 | +The other major service we need is the [k6-operator](https://grafana.com/docs/k6/latest/testing-guides/running-distributed-tests/) which is responsible for actually running the tests based on the TestRun manifests being applied to the cluster. The k6 operator is also deployed via a Helm Chart. |
| 149 | + |
| 150 | +The last service is [Sealed Secrets](https://github.com/bitnami-labs/sealed-secrets) which can be used by developers that need to inject any sort of secrets into the cluster. Sealed Secrets allows for Secrets to be encrypted locally and commited to a Github repo. Only the controller running in the cluster is able to decrypt the secrets. |
| 151 | + |
| 152 | + |
| 153 | + |
| 154 | +### Potential Use-Cases |
| 155 | +The [Grafana K6 documentation](https://grafana.com/docs/k6/latest/testing-guides/automated-performance-testing/#model-the-scenarios-and-workload) has a lot of good information to get started. |
| 156 | +- Smoke Tests: Validate that your script works and that the system performs adequately under minimal load. |
| 157 | + |
| 158 | +- Soak Test: assess the reliability and performance of your system over extended periods. |
| 159 | + |
| 160 | +- Average-load test: assess how your system performs under expected normal conditions. |
| 161 | + |
| 162 | +- Stress test: assess how a system performs at its limits when load exceeds the expected average. |
| 163 | + |
| 164 | +# Drawbacks |
| 165 | +[drawbacks]: #drawbacks |
| 166 | + |
| 167 | +# Rationale and alternatives |
| 168 | +[rationale-and-alternatives]: #rationale-and-alternatives |
| 169 | + |
| 170 | +The ideas is to share resources between teams and have a 'golden path' for testing. |
| 171 | +There is currently a request to be able to assign costs to different teams that I haven't considered. |
| 172 | +I'm not sure if tools such as kubecost can make these calculations for us or if we need to, for example, |
| 173 | +dedicate specific node pools per team and rely on tags/labels on the nodes to assign cost to individual teams. |
| 174 | +The initial design was to share resources as much as possible to keep costs down. |
| 175 | + |
| 176 | +# Prior art |
| 177 | +[prior-art]: #prior-art |
| 178 | + |
| 179 | +TODO: Get an overview of what Dagfinn, Core? and other teams were doing previouly. |
| 180 | + |
| 181 | +# Unresolved questions |
| 182 | +[unresolved-questions]: #unresolved-questions |
| 183 | + |
| 184 | + |
| 185 | +# Future possibilities |
| 186 | +[future-possibilities]: #future-possibilities |
| 187 | + |
| 188 | +- Simplify manifest generation. Most of the setup is boilerplate so we should be able to abstract most things. |
| 189 | +- Add support to deploy the tests with a volume mount instead of a ConfigMap. |
| 190 | +- Improve Dashboards experience, e.g. easy linking between resource usage (both for individual pods as nodes), tracing, logs, etc. |
| 191 | +- Slack and/or Github integration so teams receive feedback of their test runs. |
| 192 | +- Store pod logs and integrate the log solution from Microsoft with Grafana. |
0 commit comments