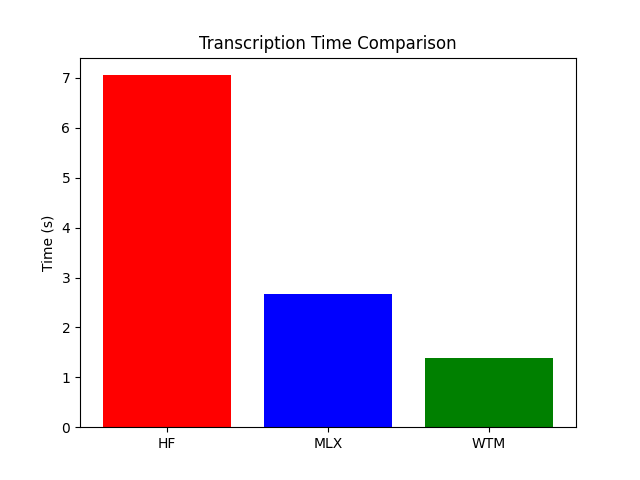
This repository provides a fast and lightweight implementation of the Whisper model using MLX, all contained within a single file of under 300 lines, designed for efficient audio transcription.
To install WTM on macOS, run:
brew install ffmpeg
git clone https://github.com/JosefAlbers/whisper-turbo-mlx.git
cd whisper-turbo-mlx
pip install -e .To install the CUDA backend on Linux, run:
pip install -e .[cuda]To install a CPU-only Linux package, run:
pip install -e .[cpu]To transcribe an audio file:
wtm test.wavTo use the library in a Python script:
>>> from whisper_turbo import transcribe
>>> transcribe('test.wav', any_lang=True)The quick parameter allows you to choose between two transcription methods:
-
quick=True: Utilizes a parallel processing method for faster transcription. This method may produce choppier output but is significantly quicker, ideal for situations where speed is a priority (e.g., for feeding the generated transcripts into an LLM to collect quick summaries on many audio recordings). -
quick=False(default): Engages a recurrent processing method that is slower but yields more faithful and coherent transcriptions (still faster than other reference implementations).
You can specify this parameter when calling the transcribe function:
wtm --quick=True>>> transcribe('test.wav', quick=True)This project builds upon the reference MLX implementation of the Whisper model. Great thanks to the contributors of the MLX project for their exceptional work and inspiration.
Contributions are welcome! Feel free to submit issues or pull requests.