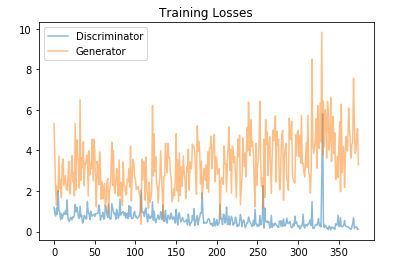
In this project, we'll define and train a DCGAN on a dataset of faces. Our goal is to get a generator network to generate new images of faces that look as realistic as possible!
The project will be broken down into a series of tasks from loading in data to defining and training adversarial networks. At the end of the notebook, we'll be able to visualize the results of your trained Generator to see how it performs; our generated samples should look like fairly realistic faces with small amounts of noise.
Project Structure
|
+-- .gitattributes
|
+-- face_generation.ipynb
|
+-- processed_celeba_small.zip
|
+-- train_samples.pkl
|
+-- assets
|
\-- processed_face_data.png
We can devide our Project in Some Steps which are given below:
- Step 1 : Pre-processed Data
- Step 2 : Visualize the CelebA Data
- Step 3 : Create a DataLoader
- Step 4 : Define the Model
- Step 5 : Training
- Step 6 : Generator samples from training
Dataset Stats We'll be using the CelebFaces Attributes Dataset (CelebA) to train our adversarial networks.
This dataset is more complex than the number datasets (like MNIST or SVHN) you've been working with, and so, you should prepare to define deeper networks and train them for a longer time to get good results. It is suggested that you utilize a GPU for training.
The CelebA dataset contains over 200,000 celebrity images with annotations. Since you're going to be generating faces, you won't need the annotations, you'll only need the images. Note that these are color images with 3 color channels (RGB) each.

A GAN is comprised of two adversarial networks, a discriminator and a generator.
Discriminator :
Your first task will be to define the discriminator. This is a convolutional classifier like you've built before, only without any maxpooling layers. To deal with this complex data, it's suggested you use a deep network with normalization. You are also allowed to create any helper functions that may be useful.
Generator : The generator should upsample an input and generate a new image of the same size as our training data 32x32x3. This should be mostly transpose convolutional layers with normalization applied to the outputs.
Discriminator(
(conv1): Sequential(
(0): Conv2d(3, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
)
(conv2): Sequential(
(0): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(conv3): Sequential(
(0): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(conv4): Sequential(
(0): Conv2d(256, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(FC): Linear(in_features=2048, out_features=1, bias=True)
)
Generator(
(FC): Linear(in_features=100, out_features=2048, bias=True)
(t_conv1): Sequential(
(0): ConvTranspose2d(512, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(t_conv2): Sequential(
(0): ConvTranspose2d(256, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(t_conv3): Sequential(
(0): ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(t_conv4): Sequential(
(0): ConvTranspose2d(64, 3, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
)
)