-
데이터 분석을 입문하기 위한 파이썬 데이터 분석 전처리 기본
-
Jupyter Notebook 공부
-
COVID19 Data Source by Johns Hopkins CSSE
-
브라질_olist 쇼핑몰업체의 ecommerce 데이터
- 데이터 포맷 이해
- Pandas 기본 문법
- 탐색적 데이터 분석
- 데이터 전처리를 위한 Pandas 라이브러리 사용법
- COVID-19 현황 분석 및 시각화
- 시각화 라이브러리 사용
- Olist Brazil Ecommerce 데이터 분석 및 시각화
- Pandas 라이브러리 기본 이해
- Series (CRUD) Create/Read/Update/Delete
[ 데이터 시리즈 Create ] pd.Series( value list, index = [index list])
- Pandas 데이터 타입 변경
Series객체.astype('변경타입')
- Dataframe (CRUD) Create/Read/Update/Delete
[ 데이터 프레임 Create ] pd.Dataframe( {key : value,...}, index = [index list])
- Dataframe에서 특정 행/열/값 가져오기
행 가져오기 : ex) df.loc[2000] 열 가져오기 : ex) df.iloc[0] value 가져오기 : ex) df.loc[2000]['미국'] or df.['미국'][2000]
- Series (CRUD) Create/Read/Update/Delete
- EDA 기본 패턴 적용을 위한 Pandas 라이브러리 문법 활용
- EDA
EDA(Exploratory Data Analysis) : 탐색적 데이터 분석
- 데이터 출처와 주제에 대해 이해
- 데이터의 크기 확인
- 데이터 구성 요소(featur)의 속성(특징) 확인
- Pandas 라이브러리로 csv 파일 읽기
doc = pd.read_csv('/파일경로/파일명', encoding = 'utf-8-sig') 뒤에 (quotechar = '구분자옵션')를 넣어서 구분자가 다른 경우도 읽기 가능하다.
- 데이터 일부 확인
head() : 처음 5개(디폴트)의 데이터 확인하기 tail() : 마지막 5개의 데이터 확인하기
- 데이터 정보 확인
shape : 데이터의 row,column 사이즈 확인 info() : column별 데이터타입과 실제 데이터 사이즈 확인
- 속성간 상관관계
corr(method = 상관계수) : 각 속성간 상관관계 확인
- EDA
- Pandas 라이브러리 데이터 가공
- Series로 feature를 보다 상세하게 탐색
Series객체.size : series의 size 반환 Series객체.count() : 데이터가 없는 경우를 뺸 사이즈 반환 Series객체.unique() : 유일한 값만 반환 Series객체.value_counts() : 데이터가 없는 경우를 제외하고, 각 값의 갯수를 반환
- 결측치(NaN) 데이터 확인
isnull() : 없는 데이터가 있는지 확인 (반환값은 bool형식으로 출력) sum() : isnull은 단지 T/F값만 반환하므로, 결측치의 총 결산을 확인하기 위해 사용 따라서, isnull().sum()을 통상적으로 사용
- 결측치(NaN) 데이터 삭제
dropna() : 모든 컬럼의 결측치를 가진 '행'을 모두 삭제 dropna(subset=[특정컬럼]) : 특정 컬럼의 결측치를 가진 행을 모두 삭제
- 결측치(NaN) 데이터를 특정값으로 일괄 변경
fillna(특정값) fillna( {'컬럼명' : '특정값',... } )
- 특정 키 값을 기준으로 데이터 합치기
groupby().sum()
- 특정 컬럼의 타입 변경
astype( {'컬럼명' : '특정값',... } )
- Dataframe에서 중복 행 확인/제거 하기
duplicated() : 중복 행 확인 함수 drop_duplicates() : 중복 행 삭제
- drop_duplicates(subset = '특정컬럼') : 특정 컬럼 기준으로 중복 행 제거
- 중복된 경우, 처음과 마지막행 중 어느 행을 남길 것인지 결정하는 방법
- keep = 'first' (디폴트 값)
- keep = 'last'
- Series로 feature를 보다 상세하게 탐색
- 데이터프레임 연결/병합을 통해 데이터 가공하기
- 두 Dataframe 연결
pd.concat( [데이터프레임1,데이터프레임2], axis = )
- 두 데이터프레임을 (위/아래) 혹은 (왼쪽/오른쪽)으로 연결
- axis : 0(디폴트)이면 위에서 아래로 합치고, 1이면 왼쪽에서 오른쪽으로 합친다.
- 두 Dataframe 병합
pd.merge(데이터프레임1, 데이터프레임2, on = 기준컬럼명, how = 결합방법)
- how 옵션 : inner / outer / left / right
- 두 Dataframe 연결
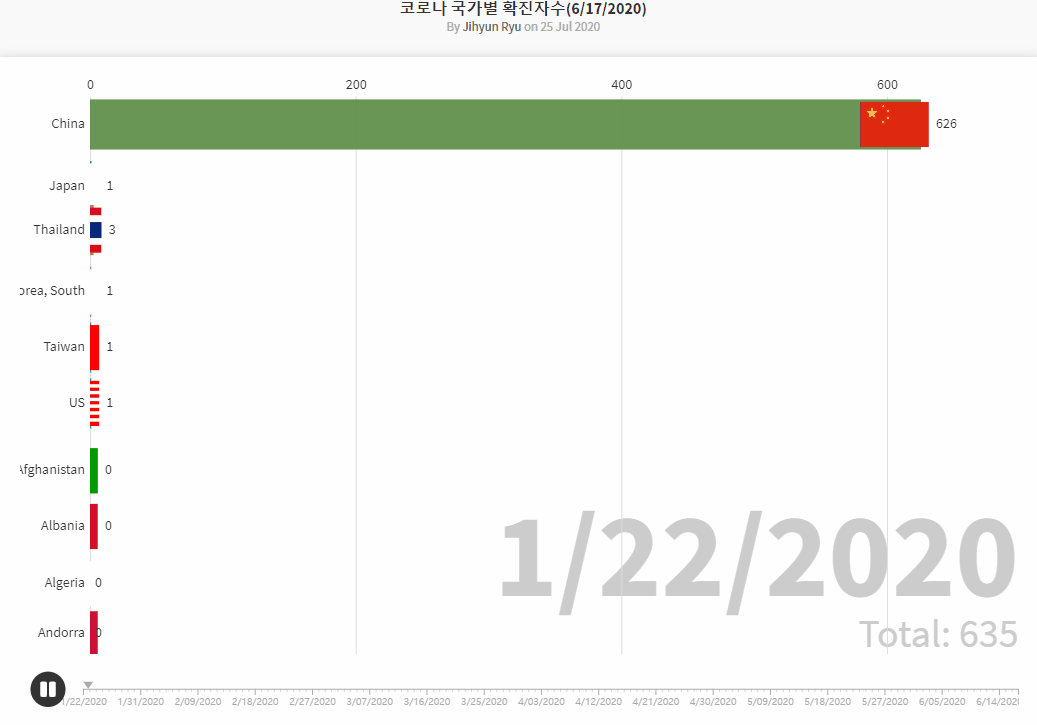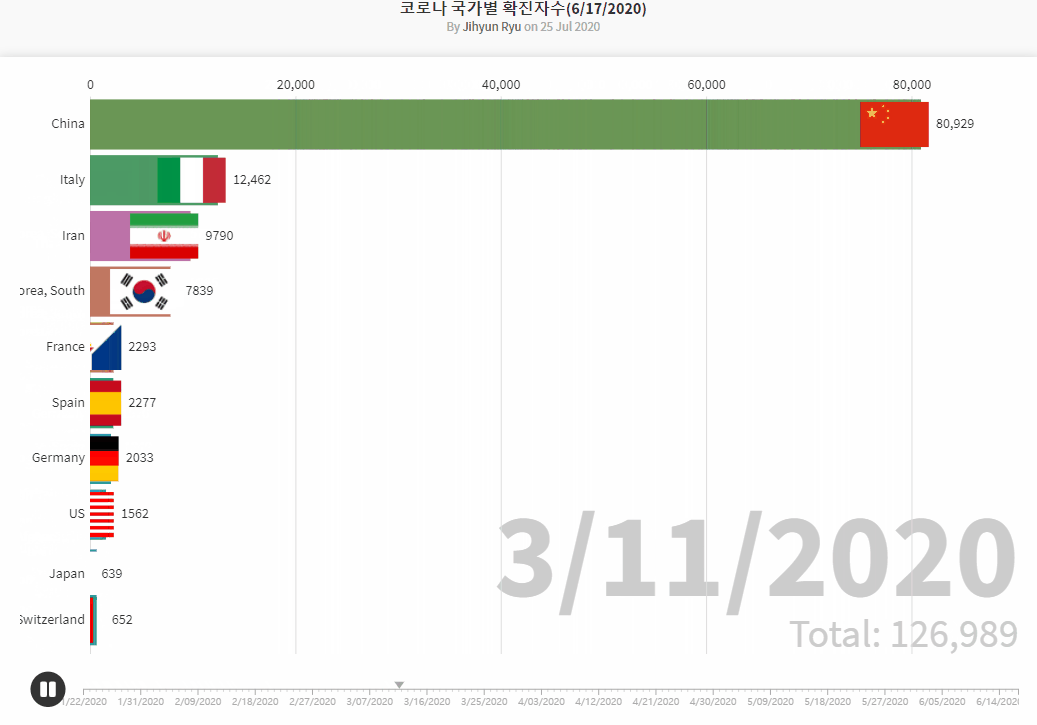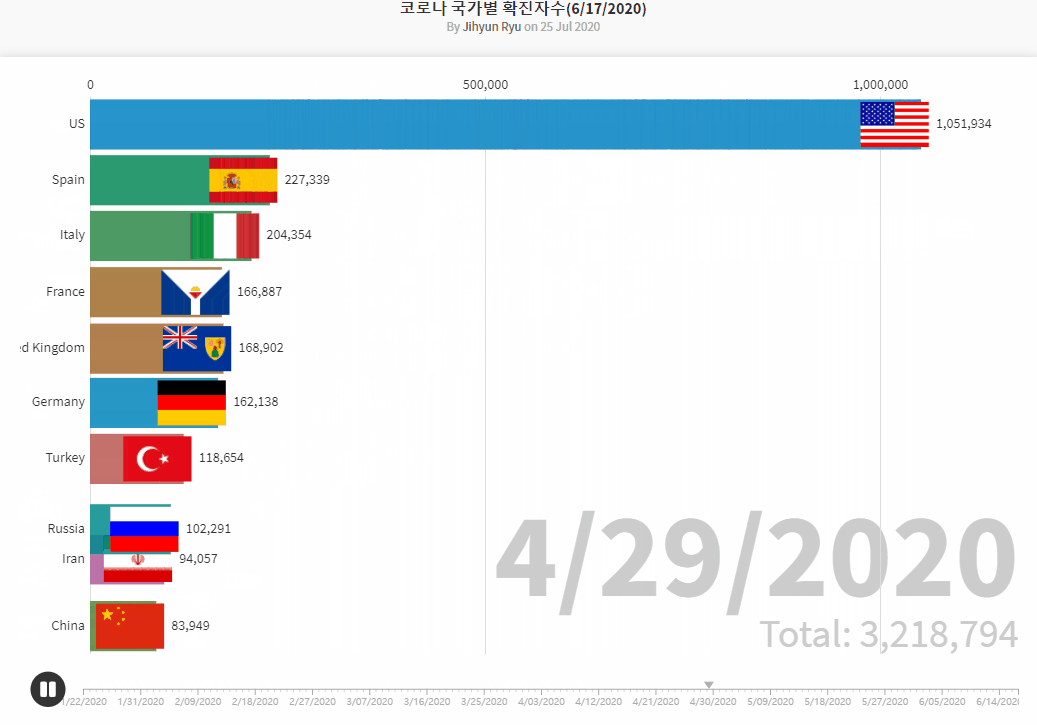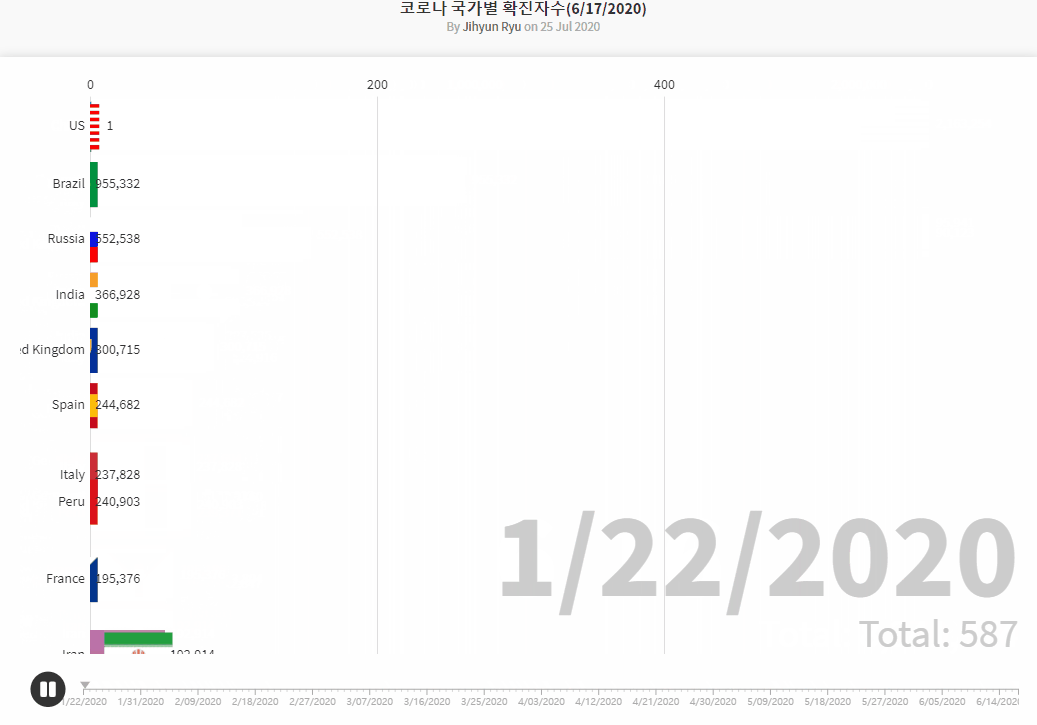
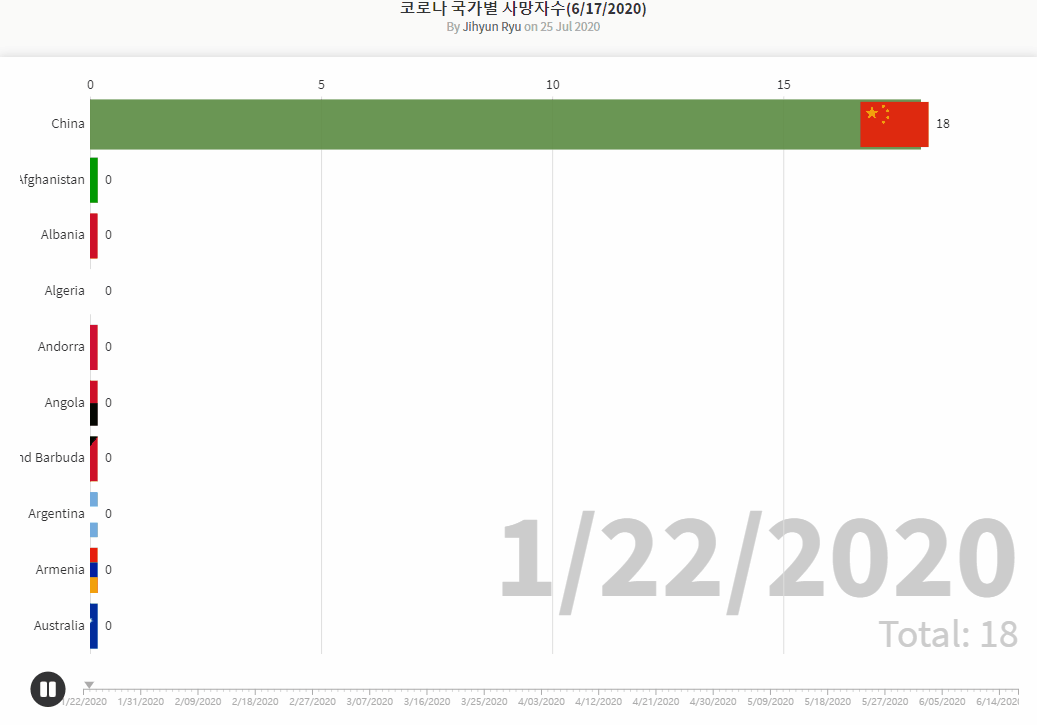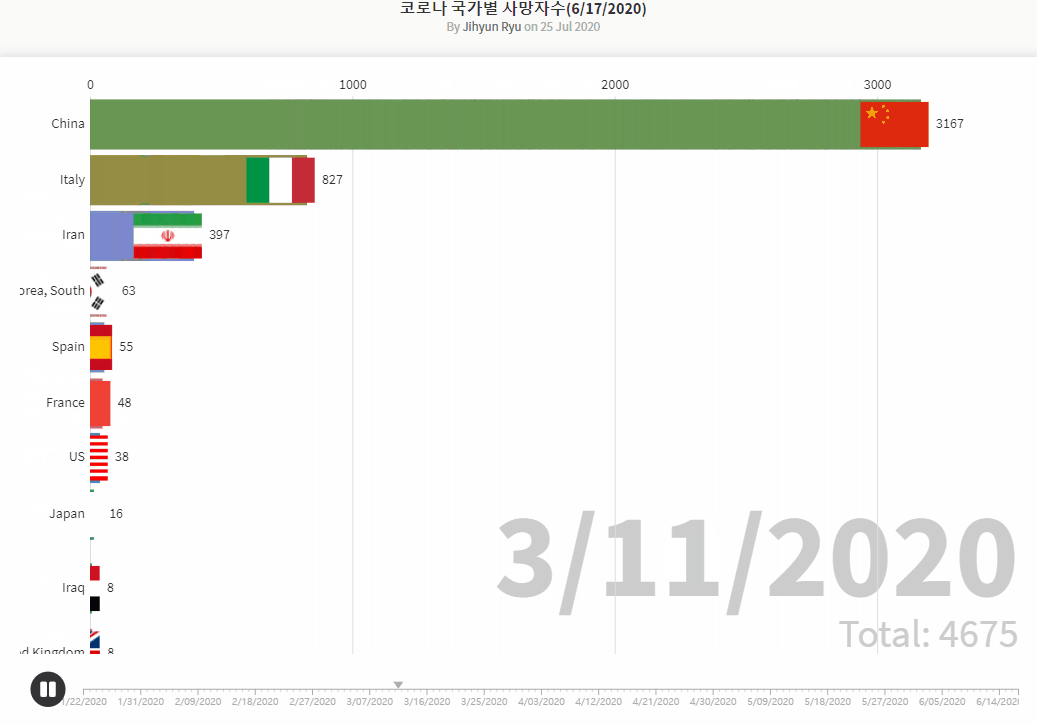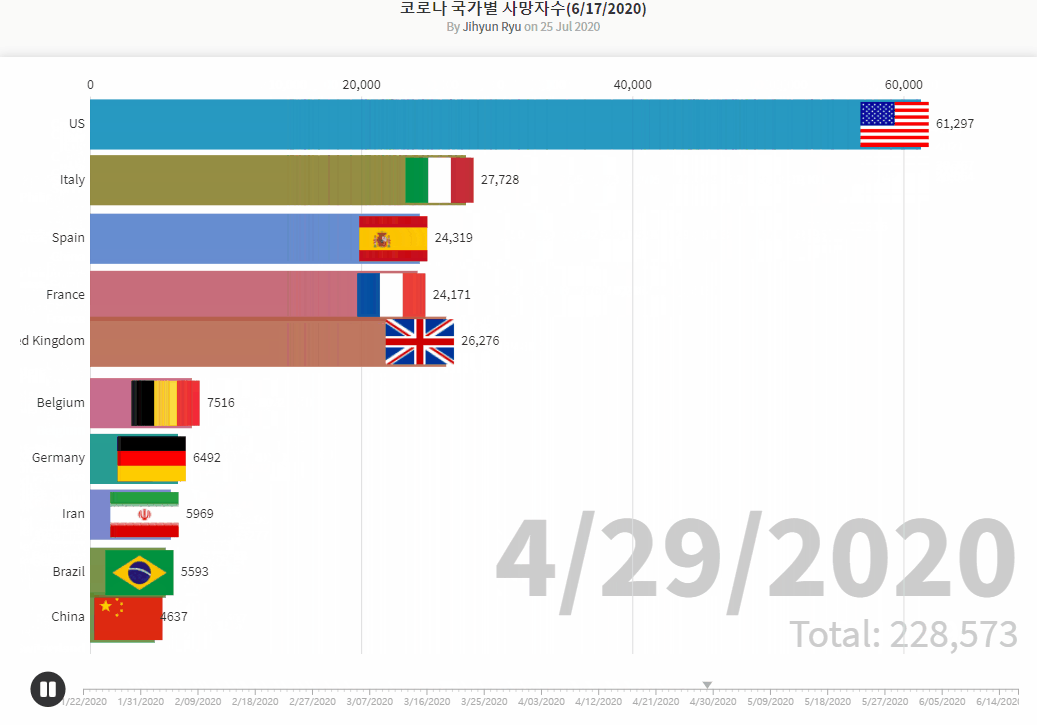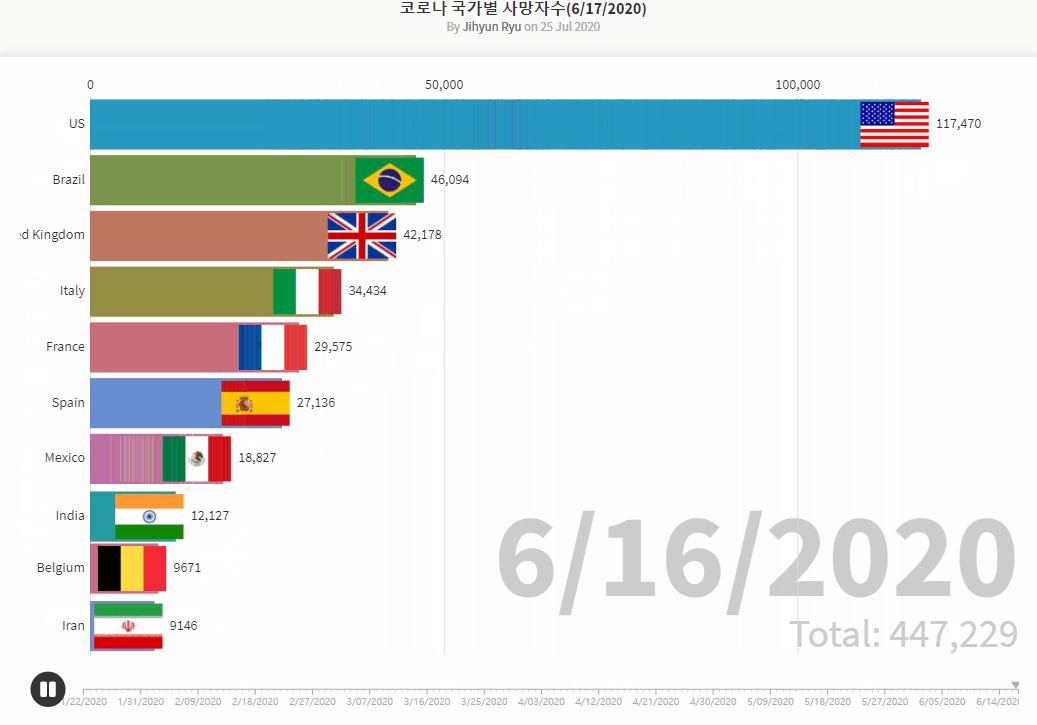
- Brazilian_Ecommerce_EDA1
- 데이터 사전 준비/이해와 EDA과정 적용
- Brazilian_Ecommerce_EDA2
- Olist 쇼핑몰을 이용하는 고객 수
- 주고객들의 거주지
- 주고객들의 지불방법
- Brazilian_Ecommerce_EDA3
- 월별 평균 거래액 분석
- 월별 거래액 시각화
- Brazilian_Ecommerce_EDA4
- 월별/일별/연도별/요일별/계절별 거래 건수 확인
- 요일/시간 간의 거래액 상관관계 분석
- Brazilian_Ecommerce_EDA5
- 카테고리별 판매/거래액 분석
- Brazilian_Ecommerce_EDA6
- 월별 평균 배송시간 분석