Awair Air Quality Dashboard
A Python CLI tool and automated data collection system for Awair air quality sensors. Provides real-time data fetching using the Awair API, historical analysis, automated S3 storage via AWS Lambda, and a web dashboard for visualization.
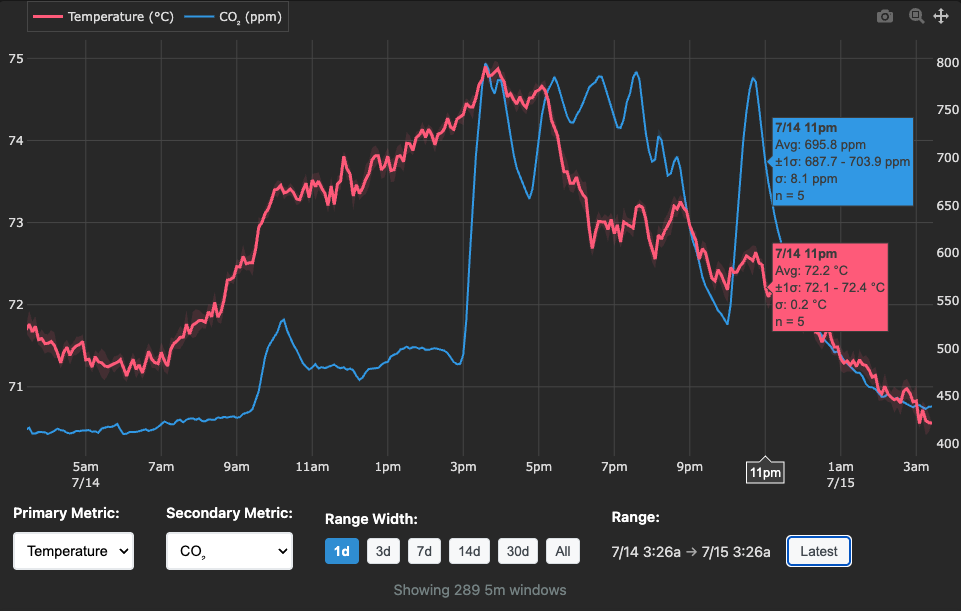
- Web Dashboard: Real-time visualization at awair.runsascoded.com
- CLI Interface: Raw data fetching, analysis, and export from Awair sensors
- Automated Collection: AWS Lambda function that collects data every 5 minutes
- S3 Storage: Efficient Parquet format with incremental updates
- Data Analysis: Built-in tools for gaps analysis, histograms, and data summaries
- Flexible Storage: Works with local files or S3 (configurable default paths)
- AWS Deployment: One-command CDK deployment with automatic IAM permissions
# Basic installation
pip install awair
# With Lambda deployment support
pip install awair[lambda]
# Development installation
pip install awair[dev]git clone https://github.com/runsascoded/awair.git
cd awair
pip install -e .Set your Awair API token via:
- Environment variable:
export AWAIR_TOKEN="your-token" - Local file:
echo "your-token" > .token - User config:
echo "your-token" > ~/.awair/token
Configure your Awair device via:
- Environment variables:
export AWAIR_DEVICE_TYPE="awair-element" AWAIR_DEVICE_ID="12345" - Local file:
echo "awair-element,12345" > .awair-device - User config:
echo "awair-element,12345" > ~/.awair/device - Auto-discovery: If not configured, the CLI will automatically detect your device on first use
Configure default data file path via:
- Environment variable:
export AWAIR_DATA_PATH="s3://your-bucket/data.parquet" - Local file:
echo "s3://your-bucket/data.parquet" > .awair-data-path - User config:
echo "s3://your-bucket/data.parquet" > ~/.awair/data-path - Default:
s3://380nwk/awair.parquet
# Fetch raw API data and save to configured data file
awair raw --from-dt 250710T10 --to-dt 250710T11
# Fetch raw API data and output as JSONL to stdout
awair raw --from-dt 250710T10 --to-dt 250710T11 -d /dev/null
# Fetch only new data since latest timestamp in storage
awair raw --recent-only
# Check your account info
awair self
# List your devices
awair devices# Show data file summary
awair data-info
awair data-info -d s3://your-bucket/data.parquet
# Daily histogram of record counts
awair hist
awair hist --from-dt 250710 --to-dt 250712
# Find timing gaps in data
awair gaps -n 5 -m 300 # Top 5 gaps over 5 minutes# Deploy automated data collector
awair lambda deploy
# View CloudFormation template
awair lambda synth
# Monitor logs
awair lambda logs --follow
# Test locally
awair lambda testSensor data is stored in Parquet format with these fields:
| Field | Type | Description |
|---|---|---|
timestamp |
datetime | UTC timestamp |
temp |
float | Temperature (°F) |
co2 |
int | CO2 (ppm) |
pm10 |
int | PM10 particles |
pm25 |
int | PM2.5 particles |
humid |
float | Humidity (%) |
voc |
int | Volatile Organic Compounds |
{"timestamp":"2025-07-05T22:22:06.331Z","temp":73.36,"co2":563,"pm10":3,"pm25":2,"humid":52.31,"voc":96}
{"timestamp":"2025-07-05T22:21:06.063Z","temp":73.33,"co2":562,"pm10":3,"pm25":2,"humid":52.23,"voc":92}The system uses AWS Lambda for automated data collection:
- Schedule: Runs every 5 minutes via EventBridge
- Storage: Updates S3 Parquet file incrementally
- Efficiency: Only fetches data since last update
- Reliability: Uses
utz.s3.atomic_editfor safe concurrent updates
The CLI seamlessly works with both local files and S3:
# Both work the same way
storage = ParquetStorage('local-file.parquet')
storage = ParquetStorage('s3://bucket/file.parquet')Lambda deployments respect user configuration:
- IAM permissions generated dynamically per S3 bucket
- Environment variables passed to Lambda runtime
- Support for any S3 bucket/key combination
pip install -e ".[dev]"ruff check
ruff formatpytestDeploy AWS Lambda function for automated data collection:
# Deploy latest PyPI version (recommended)
awair lambda deploy
# Deploy specific PyPI version
awair lambda deploy -v 0.0.1
# Deploy from local source (development)
awair lambda deploy -v source
# Build package only (no deploy)
awair lambda deploy --dry-run
awair lambda deploy -v 0.0.1 --dry-runPyPI Deployment (Default):
- ✅ Exact Versions: Deploy specific, tested releases
- ✅ Immutable: Consistent across environments
- ✅ Traceable: Clear version tracking in Lambda
- ✅ Production Ready: Uses published releases
Source Deployment (-v source):
- 🔧 Development: Test local changes before publishing
- 🚀 Latest Features: Access unreleased functionality
The Lambda deployment creates:
- Lambda Function:
awair-data-updater - EventBridge Rule: 5-minute schedule
- IAM Role: S3 permissions for target bucket
- CloudWatch Logs: 2-week retention
- Environment Variables:
AWAIR_TOKEN,AWAIR_DATA_PATH
For deployment, you need permissions to create:
- Lambda functions and layers
- IAM roles and policies
- EventBridge rules
- CloudWatch log groups
- S3 bucket access (for your target bucket)
The CLI uses a compact date format for convenience:
250710→ July 10, 2025250710T16→ July 10, 2025 at 4 PM20250710T1630→ July 10, 2025 at 4:30 PM
MIT License - see LICENSE file for details.